[0CTF 2017] engineTest (rev 261)
Задание: engineTest_81bd3eba5988a5bf7da1dae59f68df2c.zip
Дан исполняемый файл, 3 вспомогательных файла и скрипт для запуска всего этого. Открыв исполняемый файл в IDA можно увидеть как проверяются параметры и открываются все файлы переданные через аргументы.
if ( argc != 5 )
{
fwrite("[ERROR]\n", 1uLL, 8uLL, stderr);
fflush(stderr);
_exit(1);
}
if ( !strcmp(argv[1], "none") )
f_cp = 0;
else
f_cp = open(argv[1], 0);
if ( !strcmp(argv[2], "none") )
f_ip = 0;
else
f_ip = open(argv[2], 0);
if ( !strcmp(argv[3], "none") )
f_stdin = 0;
else
f_stdin = open(argv[3], 0);
if ( !strcmp(argv[4], "none") )
f_op = 0;
else
f_op = open(argv[4], 0, argv);
if ( f_cp == -1 || f_ip == -1 || f_stdin == -1 || f_op == -1 )
{
fwrite("[ERROR]\n", 1uLL, 8uLL, stderr);
fflush(stderr);
_exit(1);
}
Далее идет чтение данных с файла cp. На основании которых идет формирование ряда структур.
read_file(f_cp, &cp_m_size, 8LL);
read_file(f_cp, &cp_records_count, 8LL);
...
records = (record *)operator new[](40 * cp_records_count, &std::nothrow);
...
read_file(f_cp, records, 40 * cp_records_count);
init_cp(&cp_descr, cp_m_size, cp_records_count, records);
Как видно сперва считываются размер определенной области данных, назовем ее m. А также количество записей. И дальше идет функция init_cp, которая инициализирует структуру cp_descr на основании всех этих данных.
descr = cp_descr;
records_count = cp_records_count;
records = a4;
...
cp_descr->generated = operator new[](8 * cp_records_count, &std::nothrow);
...
v4 = (cp_m_size + 63) >> 6;
...
descr->m = operator new[](8 * v4, &std::nothrow);
...
descr->records = (record *)operator new[](40 * records_count, &std::nothrow);
...
*descr->m = 2LL; // init first 2 bits
for ( i = 0LL; i < records_count; ++i )
{
dest_record = &descr->records[i];
src_record = &records[i];
dest_record->type = src_record->type;
dest_record->q1 = src_record->q1;
dest_record->q2 = src_record->q2;
dest_record->q3 = src_record->q3;
dest_record->q4 = src_record->q4;
}
descr->m_size = cp_m_size;
descr->records_count = records_count;
generate_idx(descr);
Функция генерации немного объемна, но при этом не столь важна. Структуры description и record представляют с себя что-то такое
struct record
{
__int64 type;
__int64 q1;
__int64 q2;
__int64 q3;
__int64 q4;
};
struct description
{
__int64 m_size;
__int64 records_count;
record *records;
__int64 *m;
__int64 *generated;
__int64 record_pos;
};
Это все операции над константными значениями, которые никак не зависят от введенных данных. Получение которых и идет после функции init_cp
read_file(f_ip, &ip_count, 8LL);
...
ip_coord = operator new[](8 * ip_count, &std::nothrow);
...
for ( i = 0LL; i < ip_count; ++i )
{
read_file(f_ip, &coord, 8LL);
ip_coord[i] = coord;
}
for ( j = 0LL; j < ip_count; ++j )
{
if ( !(j & 7) )
read_file(f_stdin, &c, 1LL);
set_bit(&cp_descr, ip_coord[j], c & 1);
c = c >> 1;
}
Как видно для работы с введенными данными также нужны данные с файла ip. Т.к. у меня уже всё имеет более менее :) описывающие имена, то можно заметить, что в файле ip хранятся координаты по которым по-битово в m записываются введенные данные.
void __fastcall set_bit(description *descr, unsigned __int64 coord, __int64 bit)
{
unsigned __int64 v3; // [rsp+20h] [rbp-8h]@1
signed __int64 v4; // [rsp+20h] [rbp-8h]@2
v3 = descr->m[coord >> 6];
if ( bit )
v4 = (1LL << (coord & 0x3F)) | v3;
else
v4 = ~(1LL << (coord & 0x3F)) & v3;
descr->m[coord >> 6] = v4;
}
По функции видно, что младшие 6 бит координат используются для хранения позиции бита, а остальные 58 бит для хранения индекса для m. Зная это я написал простенький шаблон для 010 editor для парсинга файла ip
typedef struct COORD {
uint64 bit_pos:6;
uint64 index:58;
};
typedef struct IP {
uint64 count;
COORD coord[count];
};
IP ip;
И посмотрел на это всё уже по другому
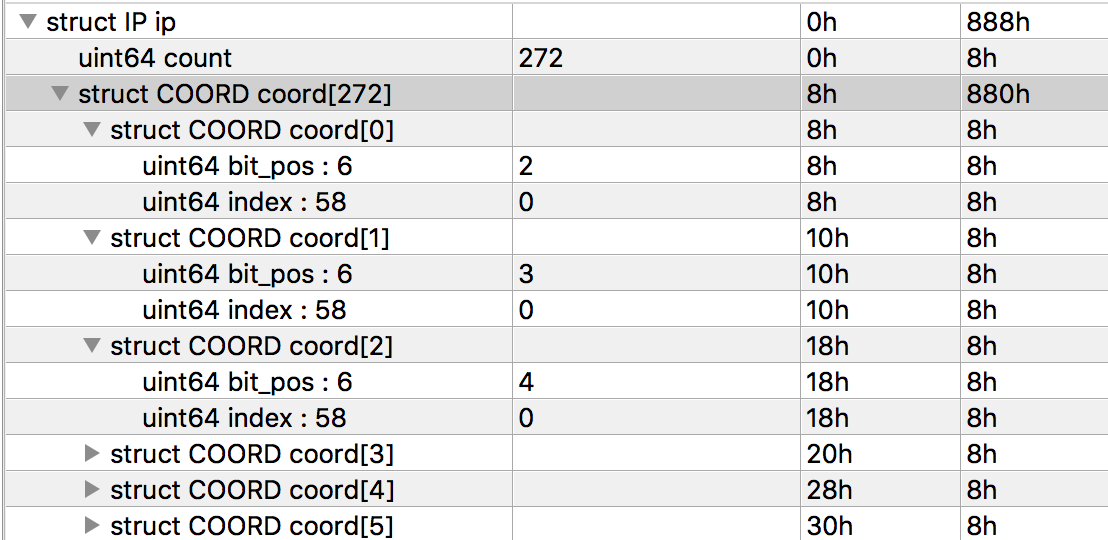
Как видно запись идет с первого элемента m, но со второго бита. Инициализацию первых двух бит можно заметить в функции init_cp. А также зная количество этих координат можно найти размер вводимых данных 272 / 8 = 34. Итак, нужно считать 34 символа флага и записать их со второго бита в m. Все как бы понятно и можно двигаться дальше. А дальше идет заполнение оставшегося пространства в m и вывод результата.
fill_m(&cp_descr);
read_file(f_op, &op_count, 8LL);
v10 = 0;
for ( idx = 0LL; idx < op_count; ++idx )
{
if ( !(idx & 7) )
v10 = 0;
read_file(f_op, &op_coord, 8LL);
v5 = get_bit(&cp_descr, op_coord);
v10 |= v5 << (idx & 7);
if ( (idx & 7) == 7 )
{
print_char(&v10, 1uLL);
}
else if ( op_count - 1 == idx )
{
print_char(&v10, 1uLL);
}
}
Принцип формирование сообщения для ответа противоположен сохранению введенных данных. Тут мы дергаем биты и с них составляем символ, который потом и выводим.
unsigned __int64 __fastcall get_bit(description *descr, unsigned __int64 coord)
{
return (descr->m[coord >> 6] >> (coord & 0x3F)) & 1;
}
Как видно формат координат в файле op такой же как и в ip. Т.ч. применив к нему тот же шаблон можно увидеть следующие

Запустив задание с неверным флагом получим в ответ " Wrong! ". Но судя по тому как формируется ответ видно, что он берет всегда биты по одним и тем же координатам. Следовательно при каких-то условиях на это место должен записаться ответ о вводе верного флага. Между вводом флага и выводом ответ есть только одна единственная функция. Скорей всего там и формируется ответ.
if ( get_bit(descr, 0LL) || !get_bit(descr, 1uLL) )
{
fwrite("[ERROR]\n", 1uLL, 8uLL, stderr);
fflush(stderr);
_exit(1);
}
for ( i = 0LL; descr->record_pos != i; ++i )
{
v10 = descr->generated[i];
q4 = descr->records[v10].q4;
q1 = descr->records[v10].q1;
q2 = descr->records[v10].q2;
q3 = descr->records[v10].q3;
type = descr->records[v10].type;
if ( type == 2 )
{
res_bit = (get_bit(descr, q1) | get_bit(descr, q2)) != 0;
}
else if ( type > 2 )
{
if ( type == 3 )
{
res_bit = get_bit(descr, q1) != get_bit(descr, q2);
}
else // type = 4
{
if ( get_bit(descr, q1) != 0 )
res_bit = get_bit(descr, q2) != 0;
else
res_bit = get_bit(descr, q3) != 0;
}
}
else // type = 1
{
res_bit = (get_bit(descr, q1) & get_bit(descr, q2)) != 0;
}
set_bit(descr, q4, res_bit);
}
Как видно ответ формируется на основании данных с файла cp. После определения типа записи выполняются определенные действия над битами по соответствующим координатам, которые хранятся в q1, q2, q3. А результат этих действий сохраняется по координатам q4. Зная структуру этого файла еще по функции init_cp я написал шаблон и для него.
typedef struct COORD {
uint64 bit_pos:6;
uint64 index:58;
};
typedef struct RECORD {
uint64 type;
COORD q1;
COORD q2;
COORD q3;
COORD q4;
};
typedef struct CP {
uint64 m_size;
uint64 records_count;
RECORD records[records_count];
};
CP cp;
Зная что координаты по которым пишется ответ находятся в поле q4, а ответ начинается по координатам (41, 543) ищем их в файле cp.
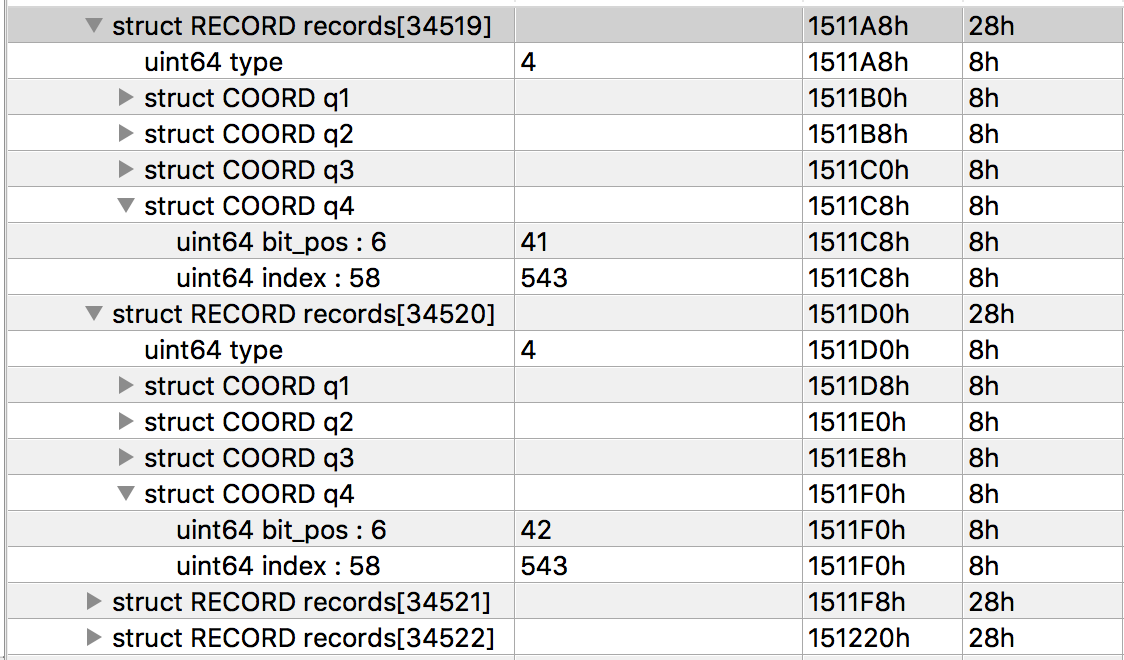
Видим, что тип этой записи 4, ищем обработку этого типа в функции выше и видим, что если бит по координатам с q1 установлен, то берем бит по координатам q2, а если нет то с q3.
if ( get_bit(descr, q1) != 0 )
res_bit = get_bit(descr, q2) != 0;
else
res_bit = get_bit(descr, q3) != 0;
Это немного проясняет ситуацию. Посмотрев координаты в q1 для записей, которые влияют на ответ было выяснено, что они все зависят от одного единственного бита по координатам (40, 543). И если он установлен, то введеный флаг верен.
Ну, теперь все ясно. Углубившись в то от чего зависит этот бит выстроилась длинная цепочка зависимостей, которую вручную не раскрутить. И тут на помощь приходит z3 :)
Осталось только все эти правила по которым устанавливаются биты перенести в него. Также мы знаем первые 2 бита этого всего, они константные и устанавливаются в функции init_cp. А также можно добавить правила на то что старший бит у символов флага всегда 0. Ну а также не забыть про тот единственный бит, который и управляет ответом :)
Полный скрипт всего этого будет выглядеть как-то так
from z3 import *
from struct import unpack_from
def solve(records):
B = []
N = 34857
for i in xrange(N):
B.append(BitVec(i, 1))
s = Solver()
for i in B:
s.add(Or(i == 0, i == 1))
s.add(B[0] == 0)
s.add(B[1] == 1)
s.add(B[34792] == 1)
for i in xrange(34):
s.add(B[2 + i * 8 + 7] == 0)
for i in xrange(len(records)):
op_type, q1, q2, q3, q4 = records[i]
if op_type == 1:
s.add(B[q1] & B[q2] == B[q4])
elif op_type == 2:
s.add(B[q1] | B[q2] == B[q4])
elif op_type == 3:
s.add(B[q1] ^ B[q2] == B[q4])
elif op_type == 4:
s.add(Or(And(B[q1] == 1, B[q2] == B[q4]), And(B[q1] == 0, B[q3] == B[q4])))
r = []
if s.check() == sat:
model = s.model()
for i in xrange(N):
r.append(model[B[i]].as_long())
else:
print 'Oops'
return r
def get_records():
with open('cp', 'rb') as f:
cp = f.read()
some_val, count = unpack_from('<QQ', cp)
res = []
for i in xrange(count):
res.append(unpack_from('<QQQQQ', cp, i * 40 + 16))
return res
def set_bit(n, b, p):
return n | (b << p)
def get_str(r, offset, lenght):
s = ''
n = 0
l = r[offset:]
for i in xrange(lenght * 8):
n = set_bit(n, l[i], i & 7)
if i > 0 and i & 7 == 7:
s += chr(n)
n = 0
return s
records = get_records()
print 'Wait'
l = solve(records)
print 'Done'
print get_str(l, 2, 34)
print get_str(l, 34793, 8)
И спустя ~20 секунд получим флаг :)
flag{wind*w(s)_*f_B1ll(ion)_g@t5s}